
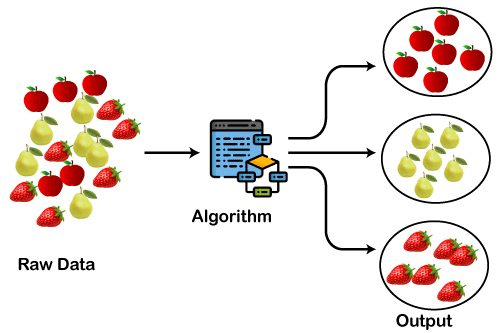
Le clustering en Machine Learning est une technique incontournable pour analyser et segmenter des données non étiquetées. Il permet de regrouper des données similaires dans des groupes appelés clusters. Contrairement à l’apprentissage supervisé, où les étiquettes sont fournies, le clustering est un type d’apprentissage non supervisé, ce qui signifie que l’algorithme doit identifier des patterns cachés dans les données.
Que ce soit pour la segmentation de clients, l’analyse de comportements utilisateurs, ou la détection d’anomalies, les méthodes de clustering comme K-means et DBSCAN sont des solutions éprouvées pour révéler la structure sous-jacente des données.
🔍 Qu’est-ce que le Clustering en Machine Learning ?
Le clustering consiste à diviser un ensemble de données en sous-groupes homogènes appelés clusters. Chaque point de données d’un cluster partage des caractéristiques similaires, et les points de différents clusters sont assez distincts. Les algorithmes de clustering sont largement utilisés dans diverses applications comme le marketing, la reconnaissance d’images, et l’analyse prédictive.
Deux des algorithmes de clustering les plus populaires sont K-means et DBSCAN. Ces techniques permettent d’analyser des volumes de données non étiquetées et d’en extraire des groupes cohérents.
🟢 K-means Clustering : Une Solution Simple et Efficace
Le K-means est un algorithme de clustering non supervisé qui regroupe les données en un nombre défini de clusters (K). Chaque point de données est attribué au cluster dont il est le plus proche, basé sur la distance euclidienne.
🔑 Comment fonctionne K-means ?
- Choix du nombre de clusters K.
- Initialisation des centres de clusters aléatoirement.
- Assignation des points de données aux centres de clusters les plus proches.
- Recalcul des centres de clusters jusqu’à stabilisation.
💡 Applications de K-means :
- Segmentation de marché : Utilisé pour regrouper des clients en fonction de leurs comportements d’achat, permettant une personnalisation plus précise des offres.
- Compression d’images : Le K-means peut réduire la taille des images tout en préservant leur qualité en regroupant les pixels similaires.
🔵 DBSCAN : Un Algorithme Basé sur la Densité pour une Meilleure Précision
L’algorithme DBSCAN (Density-Based Spatial Clustering of Applications with Noise) se distingue de K-means car il n’exige pas de définir à l’avance le nombre de clusters. Au lieu de cela, il identifie les zones densément peuplées de points et ignore les points isolés, considérés comme du bruit.
🔑 Fonctionnement de DBSCAN :
- Détection des points denses (ceux ayant un certain nombre de voisins proches).
- Expansion des clusters à partir de ces points denses.
- Les points isolés sont exclus du clustering et considérés comme du bruit.
💡 Applications de DBSCAN :
- Analyse géospatiale : Parfait pour identifier des clusters irréguliers, comme des groupes de bâtiments ou de zones naturelles.
- Détection d’anomalies : Idéal pour identifier les points de données anormaux ou hors norme dans un ensemble de données volumineux.
Pourquoi le Clustering est-il Important dans l’Analyse des Données ?
Le clustering est crucial pour toute entreprise cherchant à comprendre ses données. Il permet de :
- Segmenter des bases de données clients pour des stratégies marketing plus ciblées.
- Révéler des tendances cachées qui ne sont pas immédiatement visibles.
- Simplifier la visualisation des données en regroupant des points similaires, ce qui facilite la prise de décision.
Que vous utilisiez K-means pour des clusters simples et rapides ou DBSCAN pour identifier des formes complexes et irrégulières, ces techniques de clustering en Machine Learning sont des outils puissants pour l’analyse de données.
En Résumé : Clustering, K-means et DBSCAN en Machine Learning
Le clustering est une méthode indispensable pour explorer des ensembles de données non étiquetées. Les algorithmes comme K-means et DBSCAN offrent des solutions adaptables selon la structure de vos données. K-means est idéal pour des groupes globulaires, tandis que DBSCAN est parfait pour détecter des clusters irréguliers et gérer les outliers.
Pour en savoir plus sur la façon dont ces algorithmes peuvent transformer votre analyse de données, visitez notre site et découvrez nos services en intelligence artificielle et Machine Learning.
🌐 Visitez notre site web : www.aihorizonplusconsulting.com
